Technical Landscape Assessment: High-Performance Generative Models (Early 2026)
From vector embeddings to Transformers: Self-attention revolutionized context-aware AI. 2026 sees SMoE dominance. DeepSeek 671B activates 37B/671B via GRPO for trillion-param reasoning at mid-size speed. Hybrid attention (Qwen) & FP8 quantization enable 1M contexts efficiently.
The Evolution of Architectural Paradigms
The strategic shift from traditional Machine Learning (ML) to Transformer-based Deep Learning (DL) represents the most significant pivot in the history of computational linguistics. Early vectorization methods, such as the Document-Term-Matrix and word2vec (typically operating in 100–300 dimensions), provided the groundwork for semantic similarity but remained fundamentally "context-blind." As a strategist, it is critical to recognize that these static embeddings failed precisely where modern production demands success: they could not resolve homonyms or account for word order (semantics). The Transformer's introduction of the self-attention mechanism catalyzed the current era by enabling dynamic, context-aware representations.
Within the Transformer lineage, the industry has diverged into two primary paths: Encoder-based models (BERT-style) and Decoder-based models (GPT-style). While Encoders utilize Masked Language Modeling to understand existing text, making them suitable for Named Entity Recognition (NER) and classification, they lack the generative fluency required for complex interaction. Decoders, optimized for "Next Token Prediction," have become the global standard for 2026. This architecture's autoregressive nature allows for significantly longer context lengths and the predictive "guessing" of incomplete sequences, which is the foundational requirement for bringing models into production that are not just safe, but fast and cost-effective.
Deep Dive into Attention Optimizations and Memory Efficiency
Attention remains the primary computational bottleneck in model scaling. The standard "Scaled Dot Product Attention" carries a quadratic complexity; as context length doubles, computational and VRAM requirements quadruple. To achieve the "fast" and "cheap" nodes of our strategic triangle, several architectural variants have emerged to mitigate the Key-Value (KV) Cache bloat.
- Multi-Head Latent Attention (MLA): This represents a sophisticated compromise, projecting Keys and Values into a low-dimensional space. By compressing the Latent KV, architects can maintain high quality while significantly reducing the memory footprint during inference.
- Grouped-Query Attention (GQA): Used by models like MiniMax, this optimization shares a single Key/Value head across multiple Query heads, striking a balance between the high memory cost of Multi-Head Attention (MHA) and the quality loss of Multi-Query Attention (MQA).
- Hybrid/Linear Attention (Qwen3.5): Qwen utilizes a "Gated DeltaNet" and "Gated Attention" approach, alternating three linear layers with one full attention layer. This configuration (similar in efficiency to the Mamba architecture) bypasses quadratic complexity while utilizing a "Gated Delta Rule" to maintain the "long-term memory" that pure linear models often lack.
The "So What?" for infrastructure is clear: these optimizations are the reason Qwen can sustain a 1M token context window while traditional dense models struggle at 128K. By reducing the reliance on the KV Cache through these gated and hybrid mechanisms, we can scale context without a linear explosion in hardware OpEx.
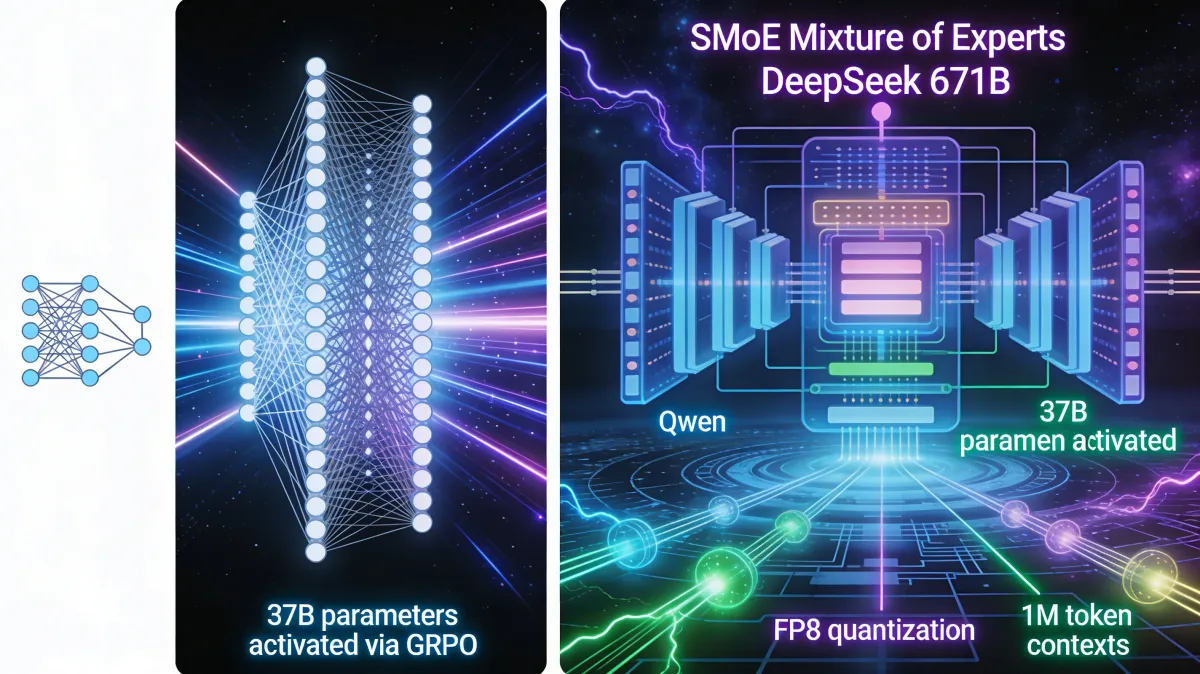
Sparse Mixture of Experts (SMoE) vs. Dense Architectures
In 2026, SMoE is the mandatory architecture for any model exceeding 100B parameters. The economic necessity is simple: we must decouple total knowledge (Total Parameters) from inference cost (Active Parameters).
The DeepSeek 671B architecture is the current benchmark for this efficiency. It utilizes a "Router" mechanism to activate only 8 experts per request from a pool of 256, resulting in only 37B active parameters during inference. This 671B/37B split provides the reasoning depth of a trillion-parameter model with the speed and token-cost of a mid-sized model. Strategic synthesis of the 2026 market shows a trend of consolidation; notably, Moonshot AI’s Kimi K2.5 utilizes the DeepSeek architecture to achieve its 1000B scale. Whether it is NVIDIA’s Nemotron-3 or LiquidAI’s specialized LFM variants (which utilize SMoE configurations ranging from 32 to 64 experts), sparsity is the only viable path to achieving the “cheap” requirement in high-volume production.
Comparative Analysis of Leading 2026 Model Specifications
Raw parameter count is no longer the sole metric for model "power." For an infrastructure architect, the interplay between context length, precision, and architectural sparsity defines the actual utility of the stack.
Technical Specifications Matrix: Early 2026 Leading Models
| Provider / Model | Parameters | Data Type | Context Length | Training Methodology | Architecture Details |
|---|---|---|---|---|---|
| DeepSeek | 671B | FP8 | 128K | GRPO | SMoE 256/8/1 |
| Moonshot AI (Kimi K2.5) | 1000B | FP8 | 256K | GRPO/Muon | SMoE 384/8/1 |
| Qwen | 0.8B-397B | BF16/FP8 | 1M | GRPO, Million Agent | Hybrid/Linear/Gated (z.T. SMoE) |
| GPT-OSS | 20B, 120B | MXFP4 | 128K | GRPO | SMoE 32-128/4 |
| LiquidAI | 1.2B, 24B | BF16 | 32K | Multi-Stage RLHF | z.T. SMoE 32-64/4 |
| NVIDIA Nemotron-3 | 20B, 120B | BF16, FP8, NVFP4 | 1M | GRPO | SMoE 512/22 128/6 |
Training Innovations: The Shift to Reasoning and GRPO
The "Reasoning Model Boom" of early 2026 marks the end of traditional RLHF’s dominance. The new standard is Group Relative Policy Optimization (GRPO). Unlike the older PPO, which required a complex Value Model, GRPO utilizes "Group Computation" to evaluate multiple model outputs simultaneously.
A critical technical detail in the GRPO loop is the use of a Reference Model to calculate KL divergence. This ensures the model’s reasoning capabilities do not drift into instability while it learns to solve complex, automatically verified problems. The resulting training pipeline has become standardized for models like DeepSeek R1:
- Base-Training: Mass data ingestion.
- Cold Start (SFT): Initial instruction alignment.
- Reasoning RL (GRPO): Training for "reasoning with justification" using verified solutions.
- SFT + Rejection: Refining outputs using synthetic data and rejecting invalid logic.
- Alignment (GRPO): Final safety and helpfulness tuning.
Infrastructure Planning: Precision, Quantization, and VRAM
Hardware-level optimizations are no longer optional; they are a survival response to GPU scarcity. In the 2026 landscape, DeepSeek’s reliance on low-level PTX (Parallel Thread Execution) is a direct strategic response to chip export restrictions ("Exporte nicht erlaubt"). By bypassing standard CUDA abstractions, they achieve high performance on limited hardware, resulting in a significant advantage in "dollars per token."
- FP8 (DeepSeek/Kimi/Qwen/NVIDIA): Now the standard for performance, FP8 saves 50% VRAM and doubles inference speed compared to BF16. While the initial training process is more complex, the OpEx savings are non-negotiable for "cheap" operations.
- MXFP4 (GPT-OSS): This proprietary format offers extreme optimization but presents a high risk of vendor lock-in. It is highly optimized but only runs on specific hardware, potentially compromising the "safe" node of the triangle regarding long-term infrastructure flexibility.
Professional Recommendation: To balance the "Cheap/Fast/Safe" triangle, infrastructure scaling should follow a two-pronged approach. For high-volume, cost-sensitive reasoning tasks, the DeepSeek/Kimi SMoE architecture (leveraging FP8 and PTX optimizations) provides the best "cheap" and "fast" metrics. However, for large-scale document processing, Qwen’s Hybrid "Gated DeltaNet" architecture is the superior choice to handle 1M token windows without the quadratic hardware penalty. The 2026 landscape proves that architectural sparsity and automated reasoning have replaced raw scale as the primary drivers of AI ROI.