The Blueprint of Modern AI: Understanding Encoders vs. Decoders
Transformers power AI's evolution from AI → ML → DL, with Encoders (BERT) for bi-directional understanding via Masked LM, and Decoders (GPT) for generation via Next Token Prediction. Attention mechanism relates words dynamically.
Introduction: From Machine Learning to the Transformer
The evolution of artificial intelligence is marked by a steady progression toward higher abstraction and more human-like processing. This history is best summarized by the lineage: Artificial Intelligence (AI) \to Machine Learning (ML) \to Deep Learning (DL) \to Transformers.
Today, Transformers are the "engines" behind the global AI revolution. They represent a fundamental shift in how machines process sequences of data. Within this family, two primary "blueprints" have emerged to solve different linguistic challenges: the Encoder (exemplified by BERT) and the Decoder (exemplified by GPT). While they share a common ancestor, their internal logic determines whether a model is better suited for analyzing existing information or generating something entirely new.
To understand these architectures, we must first look at how they transform the "raw materials" of human language into something a machine can calculate.
The Raw Materials: Vectorization and Embeddings
Computers cannot process words as symbols; they require numerical data. The transformation of text into numbers is known as vectorization. Early methods, such as the Document-Term-Matrix (and its optimization, TF/IDF), relied on counting word frequencies. While effective for simple search, these methods failed to capture the nuances of human speech.
Modern AI uses Word Embeddings, which map words into a low-dimensional vector space (typically 100 to 300 dimensions). This allows models to perform "vector equations". For instance, calculating that the distance between "King" and "Queen" is similar to the distance between "Man" and "Woman." However, as the source context notes, even advanced static embeddings have critical failures regarding Homonyme (homonyms) and Kontext.
Comparison of Text Processing Methods
| Feature | Simple Vectorization (TF/IDF) | Word Embeddings (e.g., Word2Vec) |
|---|---|---|
| Method | Counting word frequencies in documents. | Mapping words into vector space (100–300 dimensions). |
| Semantik (Meaning) | Weak. No understanding of similar meanings. | Strong. Understands synonyms and similarities. |
| Order (Reihenfolge) | Lost. Treated as a "Bag of Words." | Limited. Struggles with specific sequence logic. |
| Context/Homonyms | None. Cannot distinguish context. | Failed (X). Static vectors cannot distinguish "Bank" (river) from "Bank" (finance). |
Caption: Comparison of text processing methods (vectorization methods)
While Word Embeddings were a massive leap forward, they remained static. To solve the problem of homonyms and context, the model requires a dynamic way to look at surrounding words in real-time.
The Engine Room: Attention as a "Referencing Mechanism"
The breakthrough that solved the context problem is the Attention mechanism, technically referred to as Referenzierung (Referencing). It answers the fundamental question: "Which words in this sentence relate to which other words?"
The Scaled Dot Product Attention
The core formula from the Transformer model:
$$Z = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Where Q, K, V are query, key, and value matrices; dkdk scales by key dimension to prevent vanishing gradients.
- Queries (Q): What the model is currently looking for (the current word being processed).
- Keys (K): The "labels" or "tags" of all other words in the sentence.
- Values (V): The actual semantic information contained within those words.
By comparing the Query against all Keys, the model assigns "attention weights," allowing it to pull the most relevant Values to define the current word's meaning in that specific context.
The Scaling Problem: This calculation is computationally intensive. The effort grows quadratically with the context length. As the text doubles in size, the processing power required quadruples. This makes long-form processing a significant engineering hurdle.
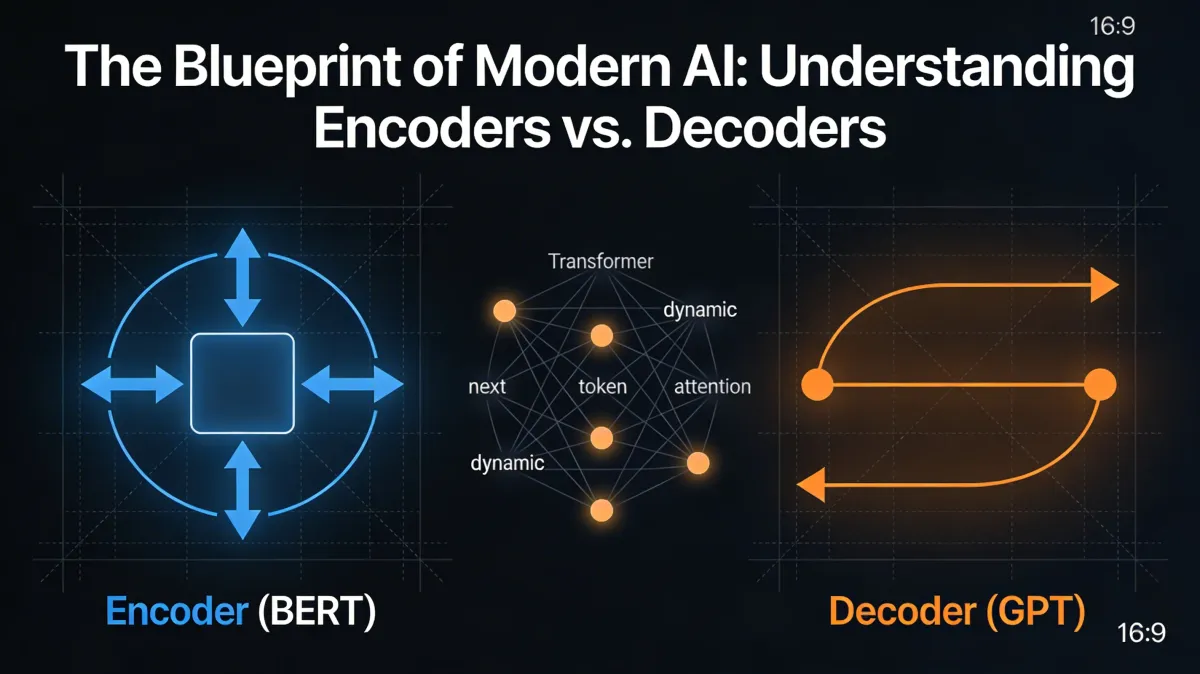
The Encoder: BERT, the Professional Reader
The Encoder architecture, with BERT as its primary representative, is built for Verstehen (Understanding). If we view AI as a workplace, the Encoder is the analytical researcher who reads a document multiple times to understand the relationships between every single word.
Analogy: The "Fill-in-the-Blanks" Test
Encoders are trained using Masked Language Modeling (MLM). This is a "Fill-in-the-blanks" test where the model is given a text with specific words hidden. Because the Encoder can look both forward and backward simultaneously (bi-directional), it uses the entire surrounding context to guess the missing word. This creates a deep, structural understanding of language.
Primary Applications for Encoders:
- Annotation & NER: Identifying and labeling entities like names, locations, or dates.
- Retrieval / RAG: Searching large datasets to find the exact information needed for a prompt.
- Sentiment Analysis: Categorizing the tone or intent of a specific text.
The Decoder: GPT, the Creative Writer
The Decoder architecture, exemplified by GPT, is optimized for Fortsetzen (Generation/Continuation). If the Encoder is the researcher, the Decoder is the creative writer who takes a starting sentence and imagines what comes next.
Analogy: The Statistical Guessing Game
Decoders are trained through Next Token Prediction. Imagine a "Statistical Guessing Game" where the model is shown a sequence and must predict the single most likely next word. It does not look "ahead" at the whole sentence like an Encoder; it looks only at what has been written so far to determine the future.
Encoder vs. Decoder Comparison
The Key Architectural Difference: while Encoders like BERT typically focus on high-precision analysis of shorter contexts (512 tokens), Decoders are designed for massive context lengths. Modern Decoders often handle 32,768 tokens or more, enabling them to maintain the "thread" of a conversation or a long document over thousands of words.
| Feature | Encoder (BERT) | Decoder (GPT) |
|---|---|---|
| Primary Goal | Verstehen (Understanding) | Fortsetzen (Generation) |
| Training Method | Masked Language Modeling: Guessing hidden words. | Next Token Prediction: Predicting the next word. |
| Key Technology | Transformer Encoder (Bi-directional) | Transformer Decoder (Unidirectional) |
| Typical Applications | Annotation, NER, and Retrieval (RAG) | Answering questions and creative writing |
| Context Length | Typically smaller (~512) | Significantly larger (32K to 1M+) |
Modern Frontiers: Optimization and Reasoning
As we push the boundaries of the Transformer blueprint, the focus has shifted toward efficiency and "thinking" capabilities. Three key optimizations define the current state of the art:
- Mixture of Experts (MoE): Models like DeepSeek use a "sparse" architecture. Rather than activating all 671 billion parameters for every word, the model is built with 256 experts, but only asks 8 experts per request. This drastically reduces energy consumption while maintaining high performance.
- Hybrid Attention (Qwen 3.5): To solve the quadratic calculation problem, new models use "Hybrid Attention." This involves alternating 3 linear layers (which process information quickly like the Mamba architecture) with 1 full attention layer. This allows the model to maintain a "long-term memory" without the massive computational cost of full attention at every step.
- Reinforcement Learning (GRPO): Beyond simple guessing, models are now trained with Group Relative Policy Optimization. This creates "Reasoning" models that don't just provide an answer; they provide a justification. The model undergoes a training loop that allows it to self-verify and provide "automatically verified solutions" to complex problems.
- Quantization: To save VRAM and increase speed, models use lower-precision data types. By representing weights as FP8 or MXFP4, developers can double inference speeds and reduce memory requirements by 50% compared to traditional formats.
Key Takeaways
Despite the move toward Hybrid Attention and Mixture of Experts, the foundation of modern AI remains the Attention mechanism. Whether a model is a professional "reader" (Encoder) or a creative "writer" (Decoder), its ability to map the intricate relationships between words is what allows it to navigate, understand, and generate our world.